并查集 Disjoint Set
在离散数学(Discrete Mathematics)中我们曾经学习过,“一个等价关系可以将一个集合中的元素划分为多个等价类”,这多个等价类就是多个不相交的集合,我们称其为并查集(Disjoint Set)。
从翻译的角度上来看,并查集和 Disjoint 好像并没有什么关系。中文上的“并查”指的是在这个数据结构上可以进行的操作:并(Union) 和查(Find)。但在英语上,只是说明了他们是 Dis_joint 的。
由于一个并查集可以看成一个等价类,所以在这个等价类中我们能找出一个代表元。也就是说,如果两个元素具有一个相同的代表元,那么他们就是属于一个并查集中。
例如:将数字 0-9 明确划分为 ${1,2,3,5,7}, {4,6,9,0}, {8}$ 三个集合;或者模运算或因子关系(如所有共享因子 2 的数)。都可以成为并查集并可以从中找出一个代表元。
代码的实现都可以基于数组,但还可以使用树结构来进行表示,这样更加直观并且更好进行后续研究。 每一个并查集都是一颗树;此时代表元就是对应元素的 parent ;开始时每个元素的 parent 都是他们自己。
查找和合并
查找
具体的实现也非常的简单,直接使用数组来实现即可,以正整数为例:索引就是不同的数字 i ,对应的值就是其所属的并查集代表元 parent[i] 。 如果查找到的元素就是它自己,那么就代表查找结束了。
1
2
3
4
5
6
size_t Disjoint_set::find(size_t i) const {
while (parent[i] != i) {
i = parent[i];
}
return i;
}
查找的时间复杂度:$T_{Find}(n)=O(h)$


上面一行是 i ,下面一行是 parent[i] 。
合并
如果想实现并这个操作的话,直接将相应元素的代表元进行修改即可。比如将4的parent设置为2。

如果需要合并的是两个根节点,那么其实只需要把其中一个连接到另一个上面即可;
如果是树内部的节点,因为他们都在一个等价类中,不能只将这个节点断开接到另一个上面,想改变他的parent其实就是要改变他所属的这个类的代表元。
那么只需要将他的代表元的parent设置为合并到的目标即可。P17-P24
1
2
3
4
5
6
7
8
9
void Disjoint_set::set_union(size_t i, size_t j) {
i = find(i);
j = find(j);
if (i != j) {
// slightly sub-optimal...
parent[j] = i;
}
}
Tips: C++中union属于保留字
对于合并这个操作,其时间复杂度为:\(T_{Set\_Union}(n)=2T_{Find}(n)+\Theta(1)=O(h)\) 找到两个节点的代表元,然后将其中一个接到另一个上面;这个操作和树的高度有关系。
我们现在知道树的高度会影响查找的性能,通过之前各种树的学习,还能发现一个树储存的信息越多(子节点越多),效率会更高。于是我们的目标就设置为:更低的高度、更宽的节点数。
先来考虑一下可能出现的最坏情况,总是将高度更高的那棵树添加到高度稍低的树上,这样,每合并一次,这棵树的高度就一定会上升,如果两棵树的高度一样,那么合并后高度会+1。
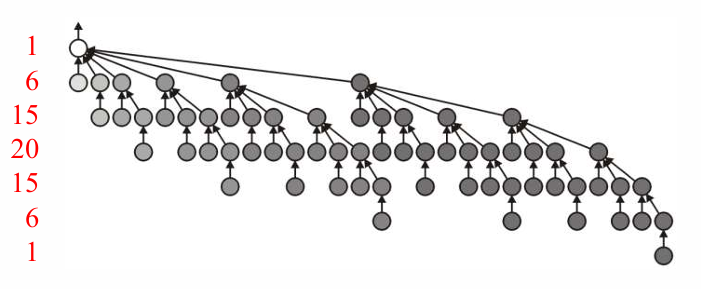
不断将高度为1、2、3、4、5的树进行最坏情况下的合并 P27
在最坏情况下的树的平均深度为 $\frac{lg(n)}{2}$ ,时间为 $O(ln(n))$ 。
最好情况下就是每个节点全部连到根节点,$\Theta(1)$
对于平均情况来说,经过实验验证(选取大量节点 $2^{15}$ 然后让他们随机合并),发现树的高度增速极其缓慢,此时基本在2-3。那么在工程的角度上来说,我们可以认为平均情况下的时间复杂度是 $O(1)$ 的。 如果严格来说,应该是 $O(\alpha(n))$ ,$\alpha(n)$ 是阿克曼函数(Ackermann Function)的逆函数,反阿克曼函数。
查找的优化
对于查找的优化,先来想想,想要找到一个元素的代表元(根节点),就要一直向上走。
向上走的过程中会路过很多元素,这些元素的代表元可能并不是我们需要的根节点(因为他们可能是被合并来的),但是他们可以将我们导向需要的根节点。如果我们能将他们的 parent 都设置为根节点的话,是不是就直接压缩树高到1了呢?这样后续如果还要进行查找的话就非常快了,并且也可以看成我们给整个路径上的节点都设置了记忆。
具体的实现其实就是这样,当find函数被调用时,就说明路过了一个节点,那么我们更新这个节点的 parent 即可:
1
2
3
4
5
6
7
8
9
size_t Disjoint_set::find(size_t n) {
if (parent[n] == n) {
return n;
}
else {
parent[n] = find(parent[n]);
return parent[n];
}
}
通过一个例子,我们可以深入了解底层的工作原理。
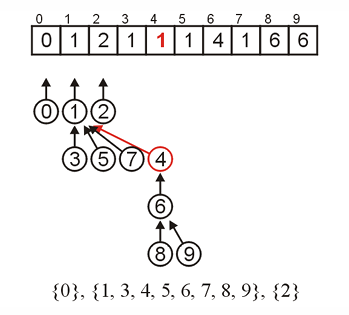
假设此时我们需要 find(9) :
1
find(9)
9的parent为6,不是9,进入else;调用 find(6)
1
2
find(6)
find(9)
6的parent为4,不是6,进入else;调用 find(4)
1
2
3
find(4)
find(6)
find(9)
4的parent为1,不是4,进入else;调用 find(1)
1
2
3
4
find(1)
find(4)
find(6)
find(9)
1的parent为1;返回1
1
2
3
4
find(1) -> return parent[1](=1)
find(4)
find(6)
find(9)
4的parent被返回值设置为1;parent[4]=1
1
2
3
find(4) -> return parent[4](=1)
find(6)
find(9)
6的parent被返回值设置为1;parent[6]=1
1
2
find(6) -> return parent[6](=1)
find(9)
9的parent被返回值设置为1;parent[9]=1
1
find(9)
返回 parent[9] 即 1。
具体应用
并查树可以被用于生成具有唯一路径的迷宫。
假设有一个迷宫由多个方格组成,每个方格都是自己的并查集。如果两个方格之间存在一堵墙,那么就将这两个方格进行合并,直到全部方格被合并完成。此时构成的树其实就是这个迷宫的结构了。
使用大模型可以进行相关实现:
prompt: 请你使用Disjoint set这个数据结构,用c++语言设计一个 $4 \times 5$ 的迷宫生成程序,要求只有一条最短路径。Disjoint set的使用可以是这样的:随机生成 $4 \times 5=20$ 个square,各自属于一个类,然后打乱。接着随机挑选两个类,如果他们是相邻的(只隔了一堵墙)进行setunion操作,直到他们都属于同一个类。
(并查集的实现看class DisjointSet即可),完整代码是可运行的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
By Gemini 3 Pro:
#include <iostream>
#include <vector>
#include <numeric>
#include <algorithm>
#include <random>
#include <ctime>
using namespace std;
// 迷宫尺寸
const int ROWS = 4;
const int COLS = 5;
// 并查集类
class DisjointSet {
private:
vector<int> parent;
public:
DisjointSet(int n) {
parent.resize(n);
// 初始化:每个元素的父节点指向自己
iota(parent.begin(), parent.end(), 0);
}
// 查找根节点 (包含路径压缩优化)
int find(int x) {
if (parent[x] == x)
return x;
return parent[x] = find(parent[x]);
}
// 合并两个集合
// 返回 true 表示合并成功(原本不在一个集合)
// 返回 false 表示已经在同一个集合(无需合并)
bool unite(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
parent[rootX] = rootY;
return true;
}
return false;
}
};
// 定义墙的结构
struct Wall {
int u, v; // 墙连接的两个单元格的索引 (0 到 19)
// 用于标记墙的类型,方便后续绘图
// type 0: u 和 v 是左右关系 (v = u + 1)
// type 1: u 和 v 是上下关系 (v = u + COLS)
int type;
};
int main() {
// 1. 初始化随机数生成器
srand((unsigned)time(NULL));
// 2. 构建所有可能的墙
vector<Wall> walls;
for (int r = 0; r < ROWS; ++r) {
for (int c = 0; c < COLS; ++c) {
int current = r * COLS + c;
// 添加右边的墙 (如果不是最后一列)
if (c < COLS - 1) {
walls.push_back({current, current + 1, 0});
}
// 添加下边的墙 (如果不是最后一行)
if (r < ROWS - 1) {
walls.push_back({current, current + COLS, 1});
}
}
}
// 3. 随机打乱墙的顺序 (模拟“随机挑选”)
// 使用 std::shuffle 以获得更好的随机分布
random_device rd;
mt19937 g(rd());
shuffle(walls.begin(), walls.end(), g);
// 4. 使用并查集生成迷宫
DisjointSet ds(ROWS * COLS);
// 记录哪些墙依然存在
// right_walls[r][c] 表示 (r,c) 右侧是否有墙
// bottom_walls[r][c] 表示 (r,c) 下方是否有墙
vector<vector<bool>> right_walls(ROWS, vector<bool>(COLS, true));
vector<vector<bool>> bottom_walls(ROWS, vector<bool>(COLS, true));
int edges_count = 0;
for (const auto& wall : walls) {
// 尝试合并墙两边的单元格
if (ds.unite(wall.u, wall.v)) {
// 如果合并成功,说明这两个格子原先不通,现在打通它们(移除墙)
int r = wall.u / COLS;
int c = wall.u % COLS;
if (wall.type == 0) {
right_walls[r][c] = false; // 移除右墙
} else {
bottom_walls[r][c] = false; // 移除下墙
}
edges_count++;
// 优化:在生成树中,边数 = 节点数 - 1。
// 20个格子,只要打通19面墙即可停止。
if (edges_count == ROWS * COLS - 1) break;
}
}
// 5. 打印迷宫 (ASCII 字符绘制)
cout << "生成的 4x5 迷宫 (S: 起点, E: 终点):" << endl << endl;
// 打印顶部边框
for (int c = 0; c < COLS; ++c) cout << "+---";
cout << "+" << endl;
for (int r = 0; r < ROWS; ++r) {
// 打印当前行的左边界
if (r == 0) cout << "S "; // 入口
else cout << "| ";
// 打印单元格内容和右墙
for (int c = 0; c < COLS - 1; ++c) {
if (right_walls[r][c]) cout << "| ";
else cout << " ";
}
// 最后一列的右边界
if (r == ROWS - 1) cout << "E"; // 出口
else cout << "|";
cout << endl;
// 打印下墙
for (int c = 0; c < COLS; ++c) {
if (bottom_walls[r][c]) cout << "+---";
else cout << "+ ";
}
cout << "+" << endl;
}
return 0;
}