计算机视觉
记录计算机视觉相关内容,包括目标检测、语义分割、样式迁移、微调等
多GPU训练和分布式训练
使用多卡进行计算的时候,一般使用数据并行的方法。对于超大模型则使用模型并行。
多gpu训练时,需要将在每个gpu上计算的各自的权重求和后重新广播到每个gpu上,使得每个gpu的参数是同步且完整的。
上述这个重新广播相当于是将各个gpu之间进行一次通信,同步信息。在并行加速的过程中,让通信的开销小于/远小于计算的开销是非常重要的。 也就是要有好的计算/通讯比,通讯一般指的是模型的大小,因为需要将模型的参数权重等信息进行同步。
数据增广
 数据增强一般是在线生成的,输入的图片还是原始数据集。但是经过在线随机变换后再给模型进行训练。
数据增强一般是在线生成的,输入的图片还是原始数据集。但是经过在线随机变换后再给模型进行训练。
对于图片来说,数据增强一般是进行
- 翻转:左右、上下(上下有时不一定可行,因为图片上下翻转可能会很怪)
- 切割:从图片中切割一块,然后变形到固定形状(为了后续计算)
- 随机高宽比(3/4、4/3)
- 随机大小
- 随机位置
- 颜色:改变色调、饱和度、亮度 以及更多的方法,具体取决于使用场景,也就是测试集的特点。并且通常增广会叠加在一起用。 增广还能有效提高测试的精度、缓解过拟合、提高模型泛化性能。
微调 FineTunning
通常一个神经网络可以被看成是这样的运行过程: 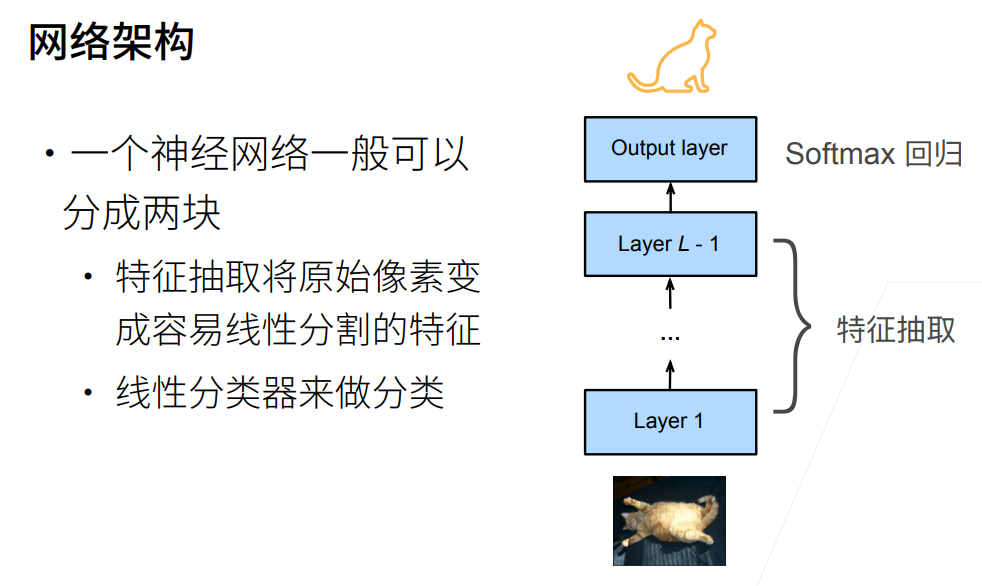 对于同样用于进行图片分类的两个数据集,正常来说特征提取基本都是一样的,因此我们可以考虑将特征提取部分的模型直接拿来对于我们自己当前的目标数据集使用。但是最后进行分类的输出全连接层还是需要重新训练。
对于同样用于进行图片分类的两个数据集,正常来说特征提取基本都是一样的,因此我们可以考虑将特征提取部分的模型直接拿来对于我们自己当前的目标数据集使用。但是最后进行分类的输出全连接层还是需要重新训练。
因此我们可以把在之前那个比较大(源数据集)的图像数据集上预训练好的模型拿过来,取其特征抽取部分。而最后部分重新训练。 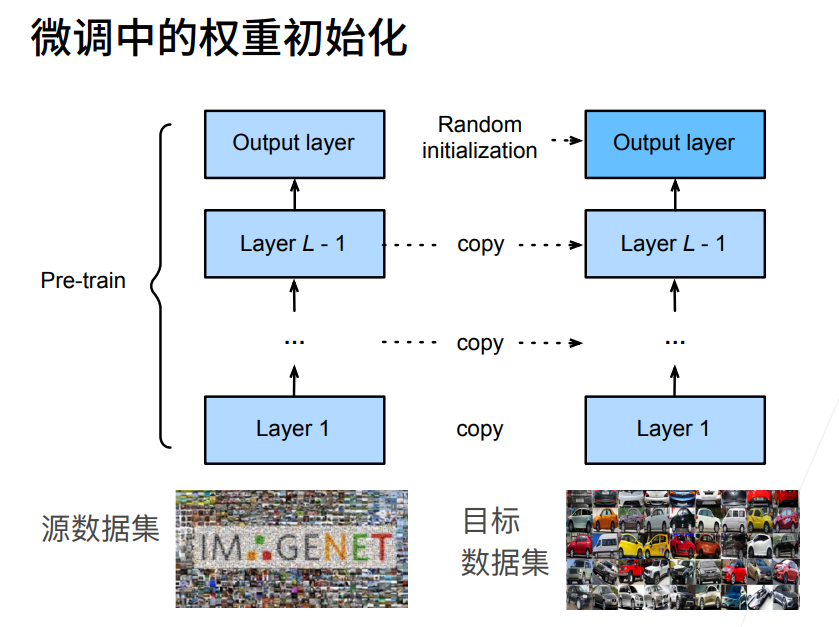 这样我们一开始就能获得一个效果还不错的预训练模型,后面只需要再根据我们的数据集进行微调即可。
这样我们一开始就能获得一个效果还不错的预训练模型,后面只需要再根据我们的数据集进行微调即可。
下图形象地展现了如何在训练数据比较少的时候通过利用预训练好的一些网络来进行微调。下层的预训练好的网络只用于提取特征信息,通常可以固定住或者只进行很小的调整。最终根据任务要求对输出层重新进行训练。 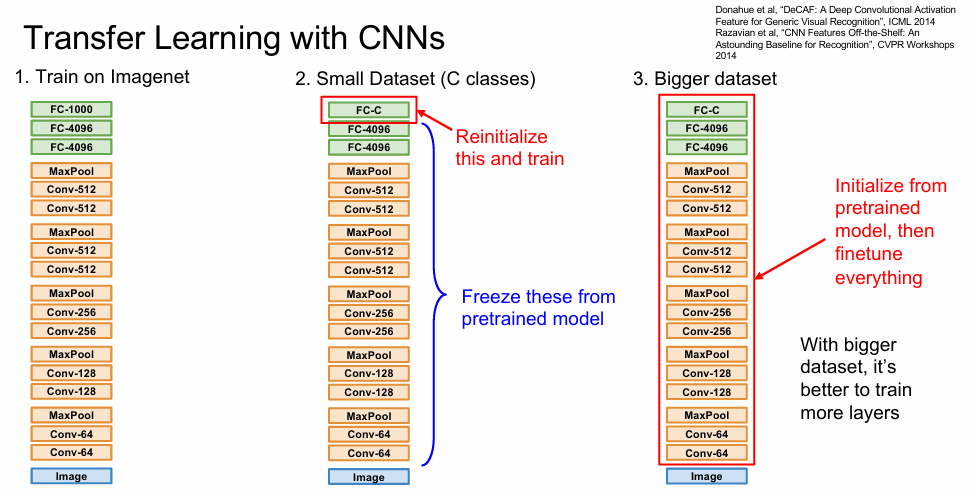
微调通常是一个目标数据集上的正常训练任务,但是使用了更强的正则化(更小的学习率、更少的epoch,告诉模型没必要再学那么多,在此基础上多学一点、学细一点或者更新一点即可)。而且通常要求源数据集远复杂于目标数据,这样微调的效果会更好。
因为源数据集通常更大,因此对于重复的部分还可以直接使用预训练模型中的分类器对应标号对应向量来做分类器(最后全连接输出层)的权重初始化。
还可以直接固定底层一些通用的层,让其不参与更新  微调就是基于一个预训练好的模型上根据目标数据集再进行调整,因此预训练模型非常重要,且微调一般速度更快,精度更高。微调可以认为是迁移学习,Transfer Training的一部分。
微调就是基于一个预训练好的模型上根据目标数据集再进行调整,因此预训练模型非常重要,且微调一般速度更快,精度更高。微调可以认为是迁移学习,Transfer Training的一部分。
物体识别和目标检测
物体识别通常需要识别图片中的多个物体类别和位置,位置一般用边缘框来表示(左上、右下的xy坐标、或者还有其他的显示方案)
锚框Anchors,常用于目标检测算法: 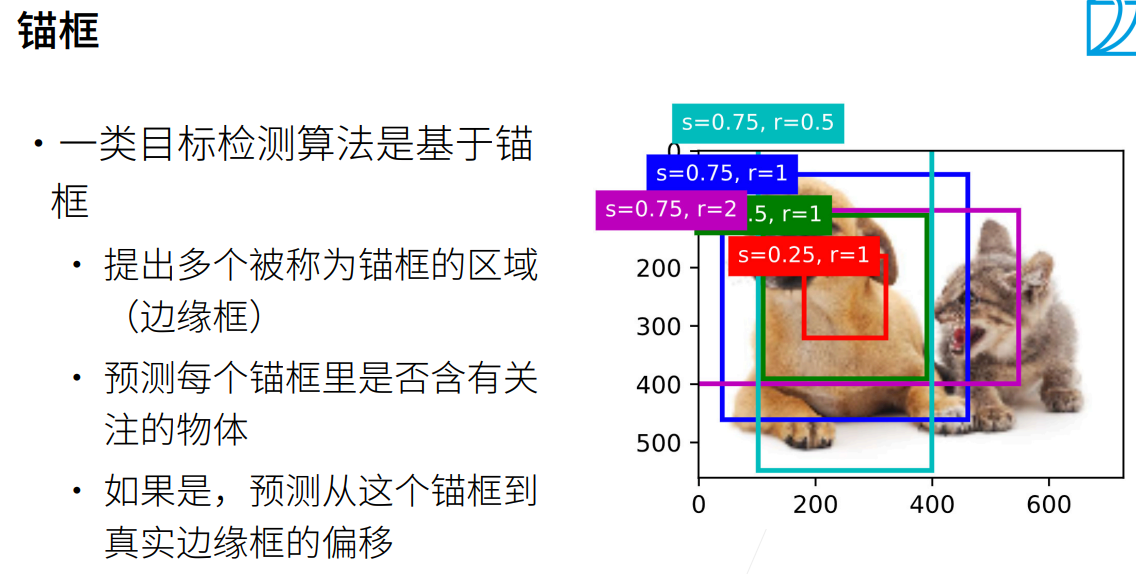 先给出多个猜测锚框,并判断是否有关注的物体,若有,再关注和真实框的偏移。 如何判断两个框之间的重合度?使用交并比,IoU,Intersection of Union
先给出多个猜测锚框,并判断是否有关注的物体,若有,再关注和真实框的偏移。 如何判断两个框之间的重合度?使用交并比,IoU,Intersection of Union 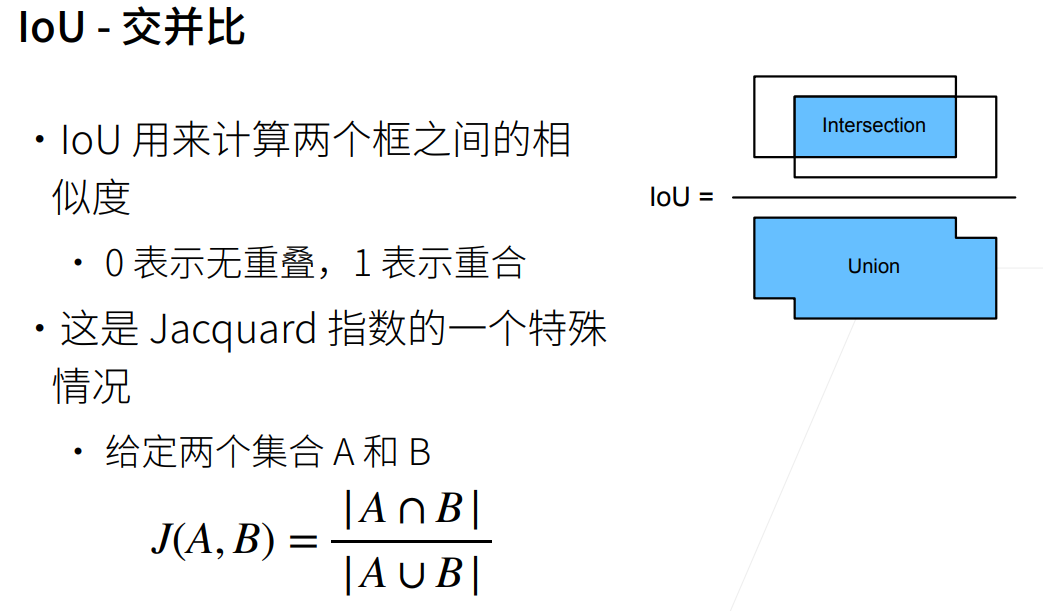 每个锚框都是一个训练样本,都需要关联:
每个锚框都是一个训练样本,都需要关联:
- 一个真实的边缘框并进行标号,以及偏移
- 或者定为一个负样本,即只框住了背景。 通常在训练任务中会产生大量的负类样本,即只框住了背景的锚框。在实际计算时会使用一个bbox_mask来讲背景样本直接设为0,让负类锚框和填充锚框不参与损失计算,且SSD使用的是L1 Loss,这样也避免了过离谱的样本对损失函数产生太大的影响。
假设我们有4个目标需要进行检测,我们给出了9个锚框,现在需要赋予锚框标号。从左到右为:依次挑出在蓝色区域(未被删掉)的IoU值最高的锚框来对应真实边缘框标号,然后删除对应的锚框行和真实边缘框列。
对于剩下的锚框可以直接全部设为负样本,但是这样会比较多,也可以直接继续做完。 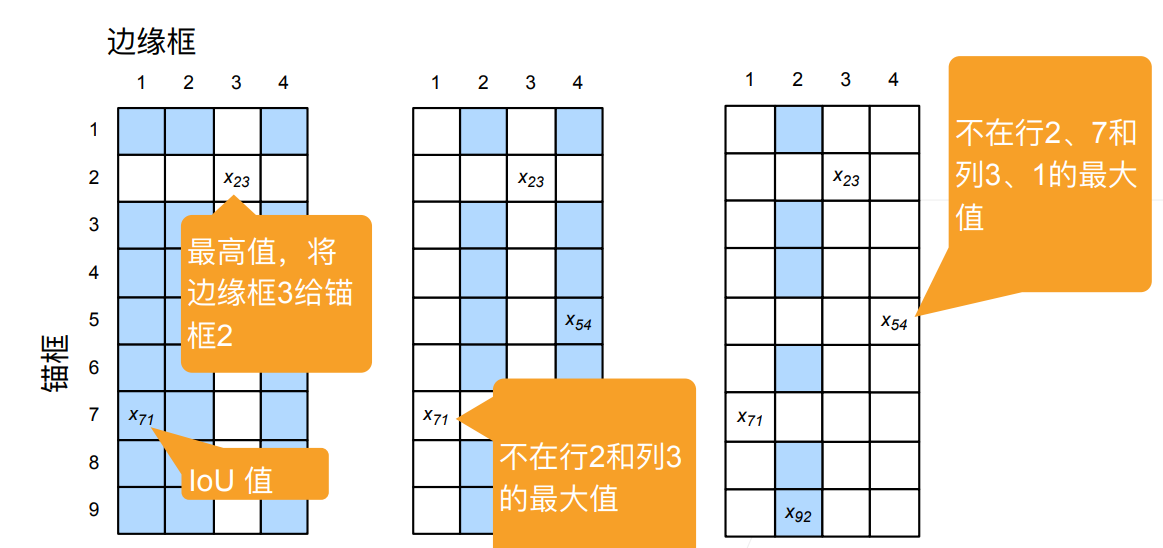 通常读入一个图片可能会有多个锚框生成,也就是多个样本,就像上面这样。 但是在预测时,我们希望能让一个锚框只对应一个边缘框,也就是需要合并其他相似的预测,可以使用NMS非极大值抑制方法。
通常读入一个图片可能会有多个锚框生成,也就是多个样本,就像上面这样。 但是在预测时,我们希望能让一个锚框只对应一个边缘框,也就是需要合并其他相似的预测,可以使用NMS非极大值抑制方法。  我们先选中了最置信的dog=0.9锚框。假设$\theta=0.5$ ,虽然dog=0.8, dog=0.7和0.9的差值小于0.5,但是和猫的差了太多,因此0.7,0.8的被去除。最终通过NMS去掉了冗余的预测。
我们先选中了最置信的dog=0.9锚框。假设$\theta=0.5$ ,虽然dog=0.8, dog=0.7和0.9的差值小于0.5,但是和猫的差了太多,因此0.7,0.8的被去除。最终通过NMS去掉了冗余的预测。
当输入一个图像进行训练的时候通常生成大量的锚框,如果每种情况都考虑的话计算量非常大,所以给定像素中心,一般只考虑 $s_1$ 缩放比和 $r_1$ 高宽比的组合:$(s_1, r_1), (s_1, r_2), \ldots, (s_1, r_m), (s_2, r_1), (s_3, r_1), \ldots, (s_n, r_1).$ 组合数量减少为 $n+m-1$ 。
在分配给锚框对应边缘框后还需要计算偏移量,offset通常会使用一些变换来使得偏移量更均匀更容易学习拟合,具体实现见代码anchor.ipynb 。最终模型学习的是锚框相对于边缘框的偏移,预测的也是偏移。
R-CNN、SSD、YOLO
R-CNN 区域卷积
较老的工作,先通过selective search选择一些不算很好的锚框,即第一点 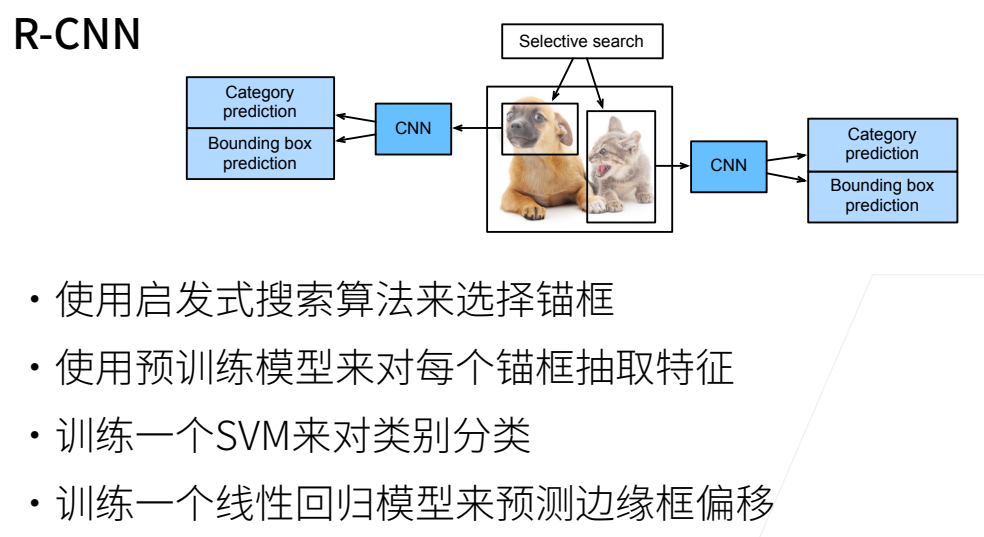 为了将生成的大小不一样的锚框转换为一个同样的batch,使用RoI(Region of Interest)。
为了将生成的大小不一样的锚框转换为一个同样的batch,使用RoI(Region of Interest)。 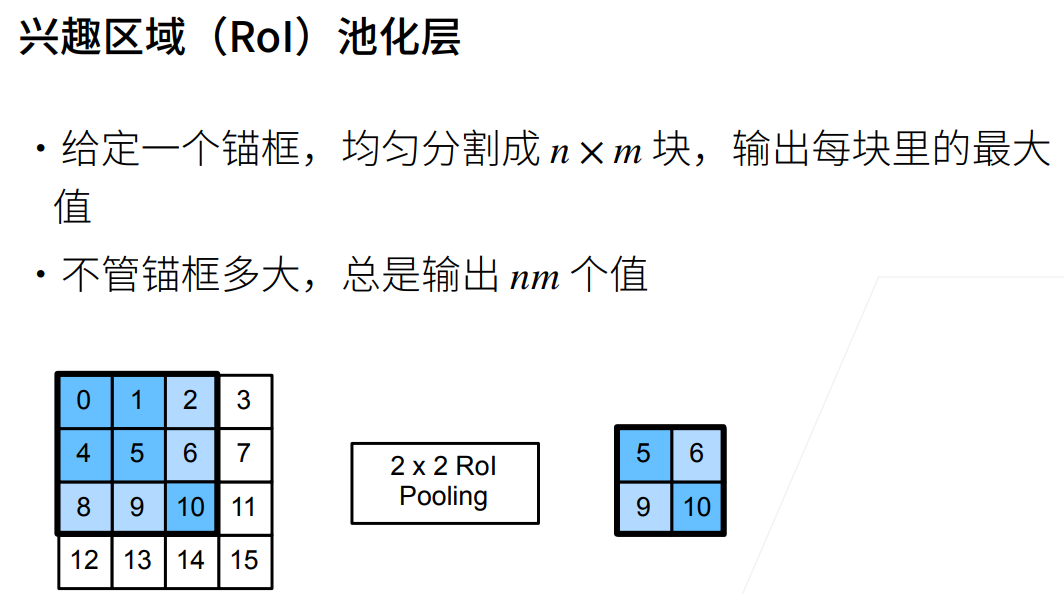 但是如果需要生成的锚框很多,那么计算就会很贵,因此我们可以先用CNN对整张图片来抽取特征,输出为一些 $32\times 32$ 的矩阵(也可能是其他大小)。然后我们再将抽出的锚框按位置比例映射到CNN后的输出矩阵,然后再进入全连接层进行预测和分类。 这样的好处是(通过图中黄框部分)免去了将一个个锚框单独进行特征抽取的大量计算。
但是如果需要生成的锚框很多,那么计算就会很贵,因此我们可以先用CNN对整张图片来抽取特征,输出为一些 $32\times 32$ 的矩阵(也可能是其他大小)。然后我们再将抽出的锚框按位置比例映射到CNN后的输出矩阵,然后再进入全连接层进行预测和分类。 这样的好处是(通过图中黄框部分)免去了将一个个锚框单独进行特征抽取的大量计算。 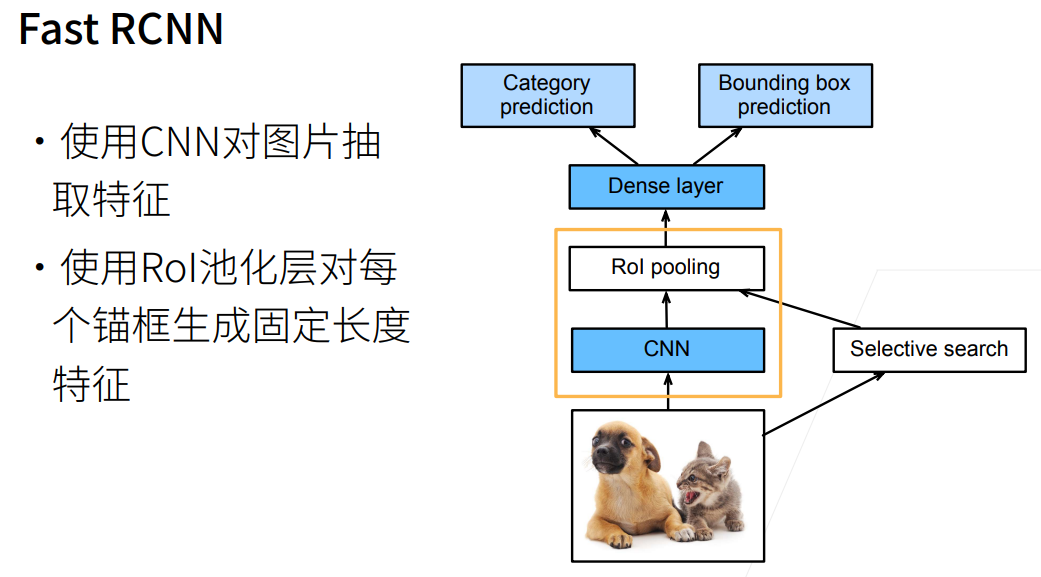 在此基础上,FasterRCNN优化了selective search部分,直接使用一个RPN来生成相对粗糙的锚框(质量会比前面大量生成的更好),相当于是预生成了一些稍差的锚框。
在此基础上,FasterRCNN优化了selective search部分,直接使用一个RPN来生成相对粗糙的锚框(质量会比前面大量生成的更好),相当于是预生成了一些稍差的锚框。 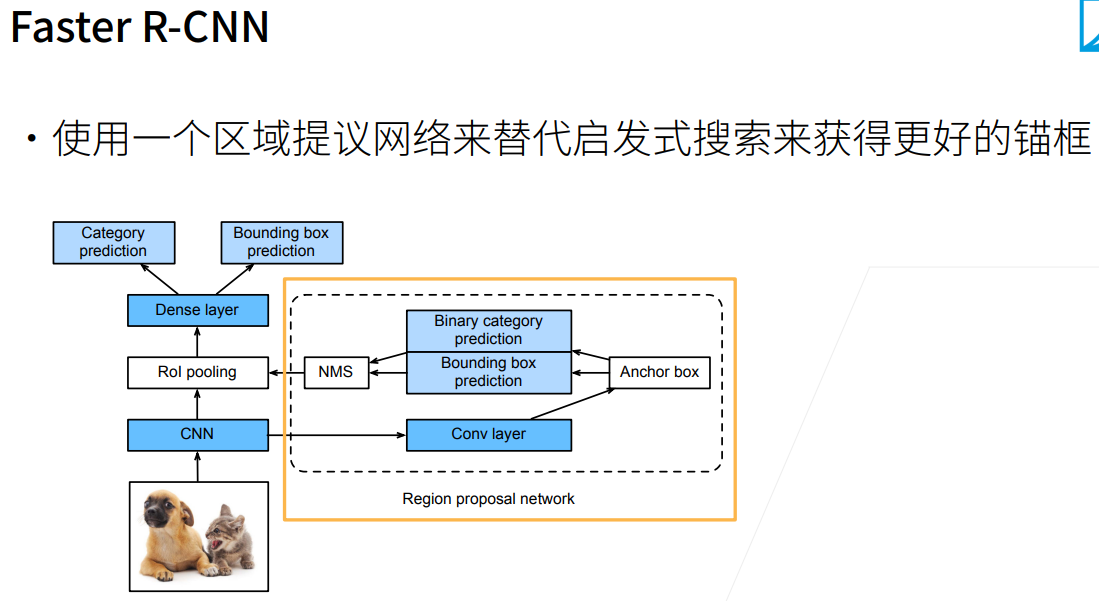 对于像素级别的标号信息,则采用MaskRCNN。
对于像素级别的标号信息,则采用MaskRCNN。
SSD单发多框检测
SSD会对每一个相同中心的像素生成多个大小的锚框,前面提到的。然后通过一个基础网络来抽取特征,最终这样的多个基础网络组合起来通过卷积层让输入高宽减半,进而不断提高网络的感受野实现从小到大的物体检测和拟合。 比如底层可能是 $64\times 64$ ,然后往上到 $32\times 32$ ,再到 $16\times 16$ .也就是多个分辨率下的检测。 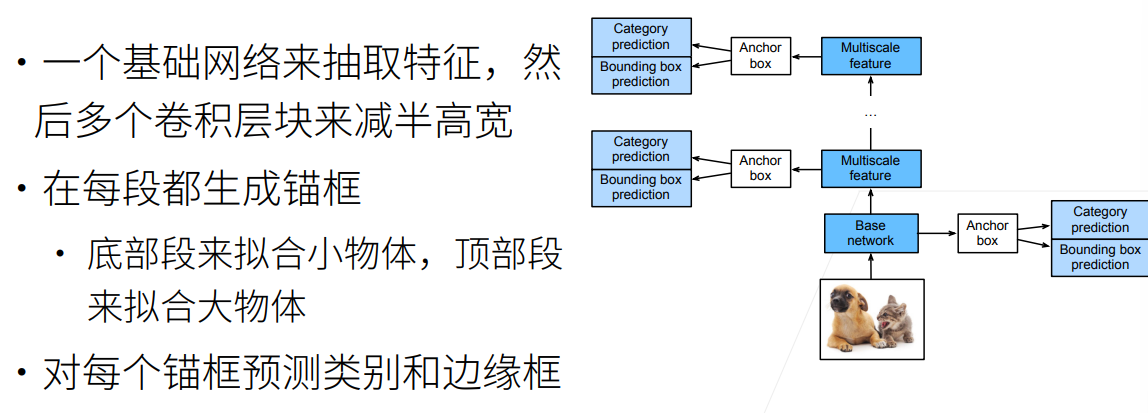 SSD的具体实现见代码。
SSD的具体实现见代码。
YOLO你只看一次
均匀分成多个不重叠的锚框,每个锚框预测多个边缘框(因为可能一个锚框会框住多个物体)。  基础思想不变,但是后续还有很多改进版本,其实是用到了很多别的地方的trick,工业界大量使用的是YOLO V3.
基础思想不变,但是后续还有很多改进版本,其实是用到了很多别的地方的trick,工业界大量使用的是YOLO V3.
语义分割(Semantic Segmentation)
语义分割可以对图片进行像素级别更加精细的分类  在语义分割中,还有实例分割,将同一类的物品(比如dog)分为dog1, dog2。 在数据增广的过程中,裁剪和旋转等操作也要将对应标号进行同样的操作,来和像素一个个对应。并且要注意固定住图片和标号的随机因子是相同的,否则虽然是同一个随机函数进行的裁剪,但是随机出的效果是不一样的。
在语义分割中,还有实例分割,将同一类的物品(比如dog)分为dog1, dog2。 在数据增广的过程中,裁剪和旋转等操作也要将对应标号进行同样的操作,来和像素一个个对应。并且要注意固定住图片和标号的随机因子是相同的,否则虽然是同一个随机函数进行的裁剪,但是随机出的效果是不一样的。
在进行RGB图像分类时,因为RGB数组难以被神经网络进行分类处理,因此需要转换为好分类的索引。这里使用的就是类似于哈希表的方法,将三个RGB值通过256进制进行求和,表示每一个样本的索引,方便对应其所属类别。
转置卷积
转置卷积和前面讲的卷积不一样,它可以将一个矩阵放大而不是缩小。主要流程为: 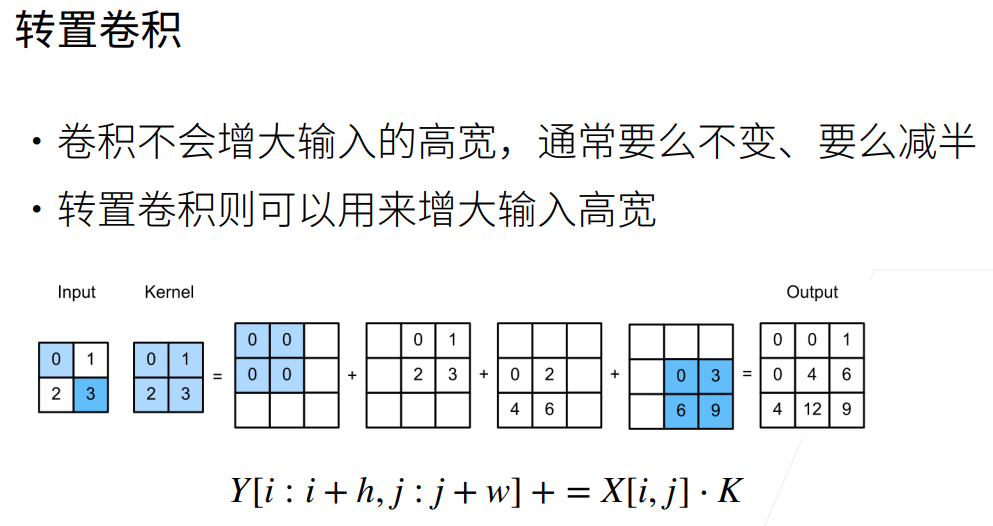 为什么叫做转置卷积?(线性代数内容)
为什么叫做转置卷积?(线性代数内容)
- 对于卷积 $Y = X \star W$ ,可以对 $W$ 构造一个 $V$,使得卷积等价于矩阵乘法 $Y’ = VX’$ (这里 $Y’, X’$ 是 $Y, X$ 对应的向量版本,$V$ 为 $m\times n$ ,则 $Y’$ 为 $m$ ,$X’$ 为 $n$)
- 转置卷积则等价于 $Y’ = V^T X’$ ($V^T$ 为 $n \times m$ ,则 $Y’$ 为 $n$ ,$X’$ 为 $m$)
上述可以总结为,如果卷积将输入从 $(h, w)$ 变成了输出 $(h’, w’)$ ,使用同样超参数的转置卷积则将输入 $(h’, w’)$ 变为输出 $(h, w)$ 。最终实现了一个与卷积相反的扩大的过程,并且这个和padding单纯增加0不同。但是转置卷积也是一种卷积,虽然实现的效果和反过来的卷积很像,但是与数学上的反卷积(Deconvolution)不能等同。在深度学习中的反卷积通常指使用了转置卷积的神经网络。
更多关于转置卷积的形状变换和解释可以看转置卷积额外的讲解 ,以及课件 。
转置卷积的计算和卷积直观上来说基本是反过来的,乘变除,+ 变 - 。并且同样有padding、stride的操作方式。
全连接卷积神经网络
FCN使用一个转置卷积层替代了原本最后的全连接层与全局平均池化层,因为最后需要的不是简单的分类,而是需要更高精度的目标检测。  关于转置卷积层的初始化一般采用的是双线性插值,这也是一种上采样的方法,这样一开始的效果其实就是将图片放大。 在预测时是在通道维度进行,对每个像素的全部通道做argmax才能实现对每个像素的标号。在预测之前还需要preprocess将图片RGB三个通道的信息进行标准化来适配预训练的模型(通常是在ImageNet上)的数据分布。
关于转置卷积层的初始化一般采用的是双线性插值,这也是一种上采样的方法,这样一开始的效果其实就是将图片放大。 在预测时是在通道维度进行,对每个像素的全部通道做argmax才能实现对每个像素的标号。在预测之前还需要preprocess将图片RGB三个通道的信息进行标准化来适配预训练的模型(通常是在ImageNet上)的数据分布。
样式迁移
将一个图像中的内容和另一图像中的风格结合起来,但是这里我们训练的不再是卷积神经网络的权重而是最终需要的图片。那么如何定义图像的内容和风格是很重要的问题。 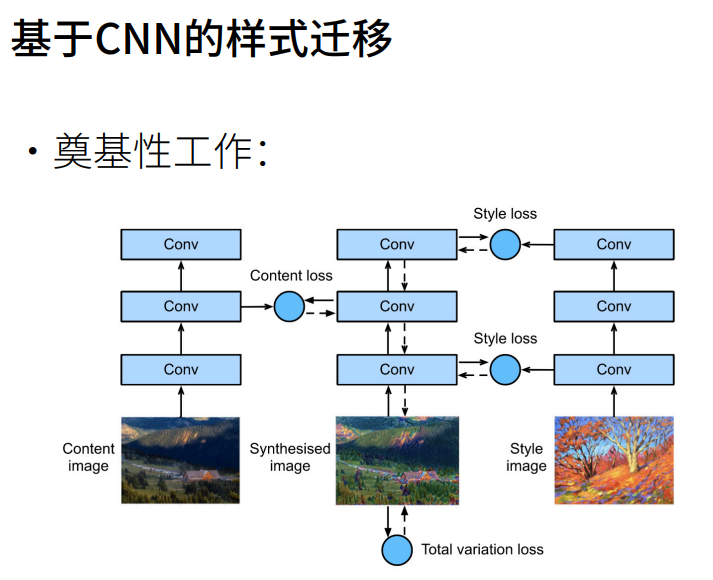 对于样式通常选择抽取不同层的特征来尽可能在全局模拟风格,而内容就不要求太多,一般只抽上层的(允许一些偏移)。样式(比如偏红、偏蓝、过曝、欠曝)体现在各个通道的统计信息和通道之间的统计信息。内容则体现在像素级别的信息。
对于样式通常选择抽取不同层的特征来尽可能在全局模拟风格,而内容就不要求太多,一般只抽上层的(允许一些偏移)。样式(比如偏红、偏蓝、过曝、欠曝)体现在各个通道的统计信息和通道之间的统计信息。内容则体现在像素级别的信息。
通过一阶统计信息(均值)和二阶统计信息(一般是方差,这里使用Gram矩阵来表示样式图像的风格)来计算样式统计信息,进而可以计算损失。
1
2
3
content_weight, style_weight, tv_weight = 1, 1e3, 10 # 各个损失的占比
...
l = sum(10 * styles_l + contents_l + [tv_l]) # 计算总损失
风格转移的损失是内容损失、风格损失和全变分损失(控制内容噪点) 的加权和。通过修改这三个损失的比例可以调整我们希望的生成图片属性。